ANALYSIS OF
FATAL ACCIDENTS
ANALYSIS OF
FATAL ACCIDENTS
ANALYSIS OF
FATAL ACCIDENTS
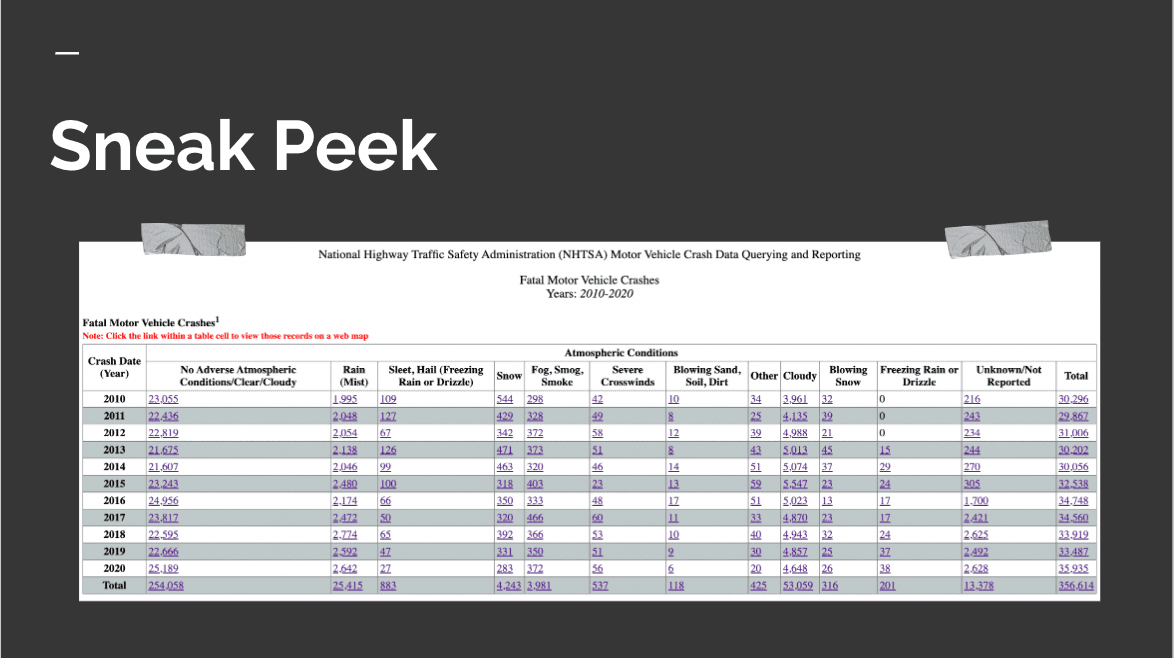
This data was in the oldest excel format possible…
2023
2023
2023
library(tidyverse) clean_csv <- function(file_path) { #input MUST be a string including the "/folder/file.csv" path df_header <- read_csv(file_path, skip = 5, n_max = 3) #Slice, then bring names together using `_` separator header_names <- paste(as.character(slice(df_header, 1)), as.character(slice(df_header, 2)), as.character(slice(df_header, 3)), sep = "_") #clean the column names header_names <- header_names %>% str_replace_all(pattern = " ", replacement = "_") %>% str_remove(pattern = "NA\\_NA|^NA\\_|\\_NA$") %>% str_replace_all(pattern = "\\.|\\,", replacement = "") %>% str_remove(pattern = "_$") #Rename first column to `Year` header_names[1] <- "Year" #read in data with cleaned names tbl <- read_csv(file_path, skip = 9, col_names = header_names, n_max = 11) #remove unnecessary columns tbl[,-length(tbl)] return(tbl) } # This function cleans all the DATE files' headers clean_date <- function(file_path) { #input MUST be a string including the "/folder/file.csv" path df_header <- read_csv(file_path, skip = 5, n_max = 3) #Slice, then bring names together using `_` separator header_names <- paste(as.character(slice(df_header, 2)), as.character(slice(df_header, 3)), sep = "_") #clean the column names header_names <- header_names %>% str_replace_all(pattern = " ", replacement = "_") %>% str_remove_all(pattern = "NA\\_NA|^NA\\_|\\_NA$") %>% str_replace_all(pattern = "\\.|\\,", replacement = "") %>% str_remove(pattern = "_$") #Rename first column to `Year` header_names[1] <- "Year" #read in data with cleaned names tbl <- read_csv(file_path, skip = 9, col_names = header_names, n_max = 11) #remove unnecessary columns #tbl <- tbl[,-length(tbl)] return(tbl) }
library(tidyverse) clean_csv <- function(file_path) { #input MUST be a string including the "/folder/file.csv" path df_header <- read_csv(file_path, skip = 5, n_max = 3) #Slice, then bring names together using `_` separator header_names <- paste(as.character(slice(df_header, 1)), as.character(slice(df_header, 2)), as.character(slice(df_header, 3)), sep = "_") #clean the column names header_names <- header_names %>% str_replace_all(pattern = " ", replacement = "_") %>% str_remove(pattern = "NA\\_NA|^NA\\_|\\_NA$") %>% str_replace_all(pattern = "\\.|\\,", replacement = "") %>% str_remove(pattern = "_$") #Rename first column to `Year` header_names[1] <- "Year" #read in data with cleaned names tbl <- read_csv(file_path, skip = 9, col_names = header_names, n_max = 11) #remove unnecessary columns tbl[,-length(tbl)] return(tbl) } # This function cleans all the DATE files' headers clean_date <- function(file_path) { #input MUST be a string including the "/folder/file.csv" path df_header <- read_csv(file_path, skip = 5, n_max = 3) #Slice, then bring names together using `_` separator header_names <- paste(as.character(slice(df_header, 2)), as.character(slice(df_header, 3)), sep = "_") #clean the column names header_names <- header_names %>% str_replace_all(pattern = " ", replacement = "_") %>% str_remove_all(pattern = "NA\\_NA|^NA\\_|\\_NA$") %>% str_replace_all(pattern = "\\.|\\,", replacement = "") %>% str_remove(pattern = "_$") #Rename first column to `Year` header_names[1] <- "Year" #read in data with cleaned names tbl <- read_csv(file_path, skip = 9, col_names = header_names, n_max = 11) #remove unnecessary columns #tbl <- tbl[,-length(tbl)] return(tbl) }
library(tidyverse) clean_csv <- function(file_path) { #input MUST be a string including the "/folder/file.csv" path df_header <- read_csv(file_path, skip = 5, n_max = 3) #Slice, then bring names together using `_` separator header_names <- paste(as.character(slice(df_header, 1)), as.character(slice(df_header, 2)), as.character(slice(df_header, 3)), sep = "_") #clean the column names header_names <- header_names %>% str_replace_all(pattern = " ", replacement = "_") %>% str_remove(pattern = "NA\\_NA|^NA\\_|\\_NA$") %>% str_replace_all(pattern = "\\.|\\,", replacement = "") %>% str_remove(pattern = "_$") #Rename first column to `Year` header_names[1] <- "Year" #read in data with cleaned names tbl <- read_csv(file_path, skip = 9, col_names = header_names, n_max = 11) #remove unnecessary columns tbl[,-length(tbl)] return(tbl) } # This function cleans all the DATE files' headers clean_date <- function(file_path) { #input MUST be a string including the "/folder/file.csv" path df_header <- read_csv(file_path, skip = 5, n_max = 3) #Slice, then bring names together using `_` separator header_names <- paste(as.character(slice(df_header, 2)), as.character(slice(df_header, 3)), sep = "_") #clean the column names header_names <- header_names %>% str_replace_all(pattern = " ", replacement = "_") %>% str_remove_all(pattern = "NA\\_NA|^NA\\_|\\_NA$") %>% str_replace_all(pattern = "\\.|\\,", replacement = "") %>% str_remove(pattern = "_$") #Rename first column to `Year` header_names[1] <- "Year" #read in data with cleaned names tbl <- read_csv(file_path, skip = 9, col_names = header_names, n_max = 11) #remove unnecessary columns #tbl <- tbl[,-length(tbl)] return(tbl) }
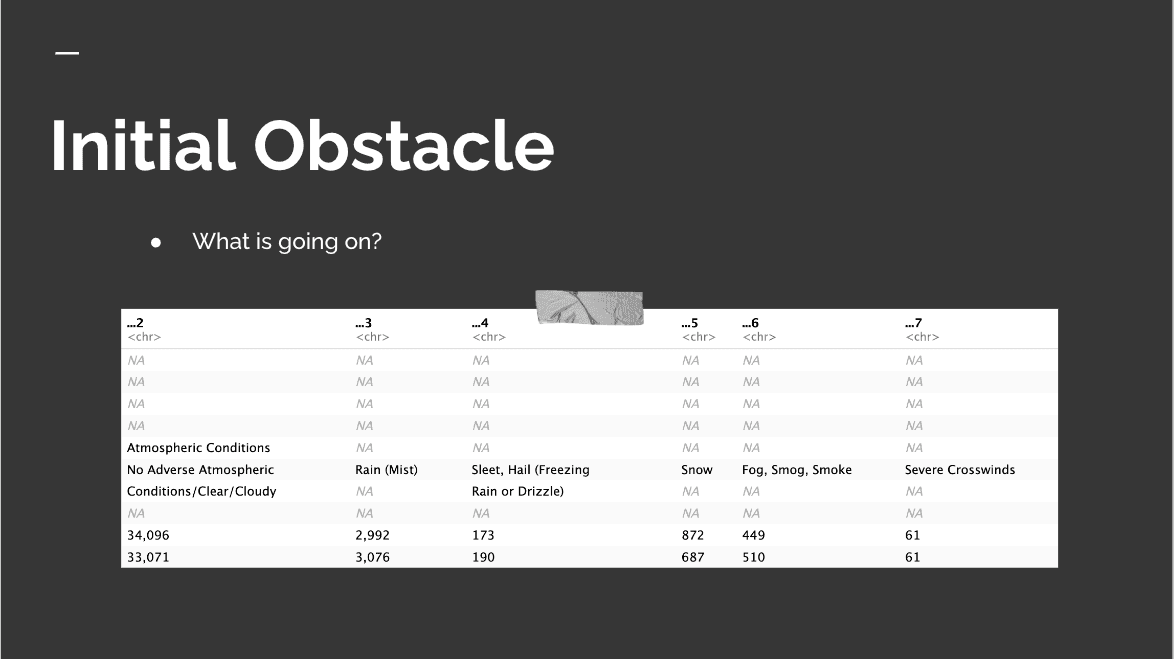
Importing the datasets was a mission. 🚀
2023
2023
2023

A function to wrangle regular expressions solved it!
A function to wrangle regular expressions solved it!
A function to wrangle regular expressions solved it!
2023
2023
2023
Overview
Sed ut perspiciatis unde omnis iste natus error sit voluptatem. Ut enim ad minima veniam, quis nostrum exercitationem ullam corporis suscipit laboriosam. Neque porro quisquam est, qui dolorem ipsum quia dolor sit amet, consectetur, adipisci velit.
Approach
Nam libero tempore, cum soluta nobis est eligendi optio cumque nihil impedit quo minus id quod maxime placeat. Nihil molestiae consequatur, vel illum qui dolorem eum. Architecto beatae vitae dicta sunt explicabo.
Framer 2023
Amsterdam